Release 2 (9.0.3)
Part Number B10061-01
Home |
Solution Area |
Contents |
Index |
| Oracle9iAS TopLink Getting Started Release 2 (9.0.3) Part Number B10061-01 |
|
Oracle9iAS TopLink is a persistence framework that allows Java applications to access relational databases and non-relational data sources. TopLink maps objects and Enterprise Java Beans (EJBs) to the database in a non-intrusive manner and enables the developer to work at the object level.
TopLink enables you to map a Java object model and Enterprise Java Beans (EJBs) to a relational database and non-relational data sources. This bridges the gap between objects and the relations that exist among them and relational databases. Objects are a very flexible way of storing data and relationships between data, so representing objects in a relational database can be complicated.
With TopLink, you can:
The TopLink framework provides a flexible, easy-to-maintain mechanism for storing Java objects and Enterprise Java Beans (EJBs) in relational database tables.
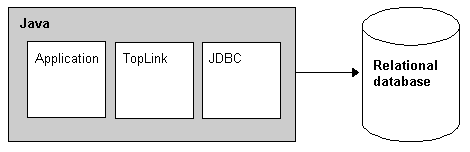
Oracle9iAS TopLink is a layer of Java code between a Java application and the relational database (as illustrated in Figure 1-1). It acts as an object-oriented wrapper around the relational database and enables an application to map its objects into a series of relational tables.
In addition to allowing applications to easily use relational databases, this model provides additional benefits:
Relational databases can store sets of information that share some common characteristics in tables. You can then build and manipulate the various relationships between these tables.
TopLink enables your application to map its objects into a series of relational tables.
Many TopLink concepts are drawn from the common components of relational databases: tables, records, and fields.
Fields organize the information in records. A table defines a standard field layout for all of its records. This layout defines both the type of information the field can contain (for example, strings, integers, float, date/time) and what that information represents (for example, employee name, department).
Figure 1-2 shows a simple Employee database table. Each row in the table is an employee record. Each column is a different field. Note that the field structure for all records is the same, and that each field can store different kinds of information (text, numbers, dates, etc.).

A relational database uses keys to relate the records in one table to records in another table. A key is a field (or combination of fields) that identifies a record or records in a table. TopLink implements the following keys:
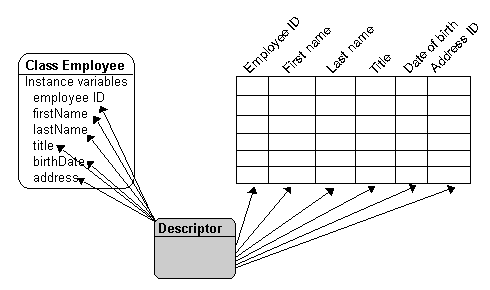
In the sample EMPLOYEE table in Figure 1-3, each employee record contains a foreign key reference to the employee's home address (that is, Address ID). Notice that John Smith and Jane Smith both have references to the same home address.
In a relational database, each record must be uniquely identified. Tables without a unique key can use sequencing to assign a unique ID to each record. For example, in the ADDRESS table in Figure 1-3, the primary key to the table is a series of sequential numbers (called sequence numbers) that identify the records being stored. Each time the application writes a new record to the database, the record receives a new sequence number (the existing value plus one).

A Java object contains the following components:
String and Date.
Object and relational database domains contain the following similarities:
Object technology introduces some concepts that may be difficult to model using relational databases, such as:
TopLink handles all of these concepts and relationships.

TopLink uses descriptors to take advantage of the similarities between relational databases and objects while accounting for their differences.
A descriptor is a set of properties and mappings that describes how an object's data is represented in a relational database. The descriptor contains mappings from the class attributes to the table columns, as well as the transformation routines necessary for storing and retrieving attributes. The descriptor links the Java object to its database representation, as it appears in Figure 1-5.
Every TopLink descriptor is initialized with the following information:
The mappings stored in each descriptor define the storage and retrieval of an object's attributes. TopLink uses two types of mappings:
Relationship mappings map relationships between TopLink-enabled objects. There are three main types of relationship mappings: one-to-one, one-to-many, and many-to-many. One-to-one mappings store the link from one TopLink-enabled class to another. One-to-many and many-to-many mappings store collections of references to other TopLink-enabled classes.
Direct mappings map attributes. There are two types of direct mappings: direct-to-field and transformation type. Direct-to-field mappings are the simplest to use; they store the attribute in the database table in the field's native format. To map attributes that are not supported by direct-to-field mappings, you must use a transformation type mapping.
Transformation type mappings transform the data from a native Java format to one supported by the relational database. Four transformation type mappings are available: object type mappings, type conversion mappings, serialized object mappings, and transformation mappings.
To learn how to build simple descriptors, refer to the tutorials and demo programs in the Oracle9iAS TopLink Tutorials. After completing the tutorial, refer to the Oracle9iAS TopLink Mapping Workbench Reference Guide for more information about the topics discussed in the tutorial.
A database session in TopLink represents an application's dialog with a relational database. The DatabaseSession class keeps track of the following information:
Project and DatabaseLogin, which store database login and configuration information
DatabaseAccessor, which wraps the JDBC connection and handles database access
An application uses the session to login to the database and perform read and write operations on the objects stored therein. The session's lifetime is normally the same as that of the application.
After the descriptors have been created, you must write Java code to register the descriptors with the TopLink session. After registering the descriptors, the application is ready to read and write Java objects from the database:
A transaction is a set of database operations that can either be committed (accepted) or rolled back (undone). Transactions can be as simple as inserting an object into a database, but also allow complex operations to be committed or rolled back as a single unit. Unsuccessful transactions can be discarded, leaving the database in its original state.
A unit of work is an object that unifies the database transaction with the changes to the Java objects, defining an object-level transaction. The unit of work enhances database commit performance by updating only the changed portions of an object. Units of work are the preferred method of writing to a database in TopLink.
Sessions can read objects from the database using the readObject() method. Database sessions can write objects to the database using the writeObject() method, but note that this method is neither required nor used when using a unit of work. An application typically uses the session to read the instances of a given class from the database and determines which of the instances require changes. The instances requiring changes are then registered with a unit of work. After the changes have been made, the unit of work is used to commit only the changed objects to the database.
This model provides the optimum performance for most applications. Read performance is optimized by using the session because the unit of work does not have to keep track of objects that do not change. Write performance is optimized because the unit of work keeps track of transaction information and writes only the changed portions of an instance to the database.
TopLink Mapping Workbench is a separate tool that provides a graphical method of configuring the descriptors and mappings of a project. It provides many checks to ensure that the descriptor settings are valid, and it also provides advanced functionality for accessing the database and creating a database schema.
TopLink Mapping Workbench does not generate Java code during development, which would be unmanageable if the descriptors changed. Instead, it stores descriptor information in an XML deployment file, which can be read into a Java application using a TopLink method. To support the development of a run-time application, TopLink can generate a .java file from the XML file, eliminating the need for TopLink Mapping Workbench files at run time.
The TopLink Mapping Workbench displays all of the project information for a given project, including classes and tables.

Refer to Oracle9iAS TopLink Mapping Workbench Reference Guide for more information on editing projects and descriptors using the Mapping Workbench.
To ensure the best design for your TopLink application, you should follow an iterative step-by-step development process and consider certain database issues, as illustrated in Figure 1-7.
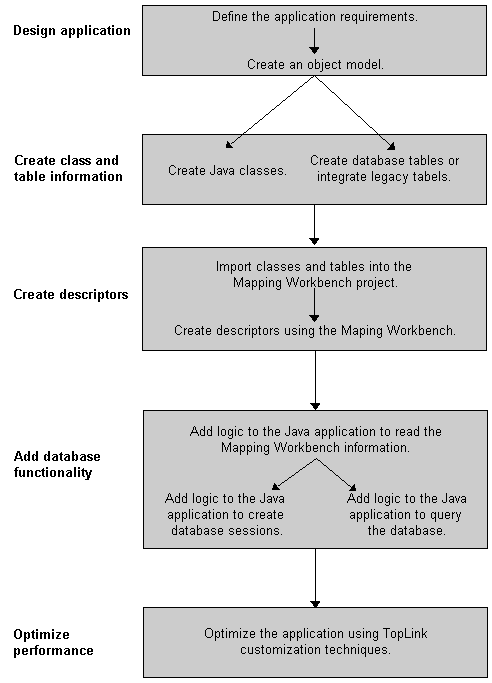
One of the most important decisions when designing a TopLink application is relating Java classes to database information. Although some designers would say that the application's object model should be designed first, and its design should drive the specification of the database schema, there are some compelling reasons why the relational database schema should be considered during the design of the object model:
Each decision regarding the attributes and relationships of and between objects affects the database implementation. These two design models are inter-related and thus, must be considered together.
As shown in Oracle9iAS TopLink Foundation Library Guide, the impact of an otherwise insignificant decision may greatly affect the performance of the database.
The application designer can save time by considering the effects of application design decisions on the design of the database.
Application designers often opt for maximum re-use when designing new applications. This sometimes results in unnecessarily fragmented object models, in which each bit of functionality is factored into a tiny reusable object. Designing and implementing a database whose schema is based on a fragmented object model can result in extremely inefficient application performance.
Do not let the design of the database drive the design of the object model, but do not design the two in isolation either. For best results, consider the database during the design of the application rather than afterwards.
|
|
 Copyright © 2002 Oracle Corporation. All Rights Reserved. |
|