Release 2 (9.0.3)
Part Number B10064-01
Home |
Solution Area |
Contents |
Index |
| Oracle9iAS TopLink Foundation Library Guide Release 2 (9.0.3) Part Number B10064-01 |
|
An enterprise application is an application that is designed to provide services to a broad range of users across an entire business. This chapter describes how to develop enterprise applications using TopLink, and discusses
This chapter also illustrates some of the TopLink features that enable it to integrate with industry-leading enterprise application servers.
Three-tier applications are an extension of the client server paradigm that separates an application into three tiers instead of two. These tiers include the client, the application server and the database server. This model allows for application logic to be performed on both the server and client tiers and is scalable to Internet deployment.
An enterprise application is one that integrates multiple heterogeneous systems. An enterprise application may need to integrate with multiple database servers, a legacy application or mainframe application. An enterprise application may also be required to support multiple heterogeneous clients such as RMI, HTML, XML, CORBA, DCOM, or telephony. The three-tier model allows for complex enterprise applications to be built through integrating with other systems in the application server tier. There are many different types of enterprise architectures.
TopLink can be used in any enterprise architecture that makes use of Java. TopLink has direct support for multiple different enterprise architectures and application server features. TopLink is not an application server but provides application server components. TopLink can also be used in a Java client and a Java supporting database server.
TopLink is certified 100% pure Java and can be used in any Java VM including:
Table 2-1 lists the features that TopLink supports for various enterprise architectures. This table can be used to determine the relevant TopLink features for your applications architecture.
Client and Server sessions provide the ability for multiple clients to share persistent resources. They provide a shared live object cache, read and write connection pooling, parameterized named queries and share descriptor metadata. Client and server sessions should be used in any application server architecture that supports shared memory and is required to support multiple clients.
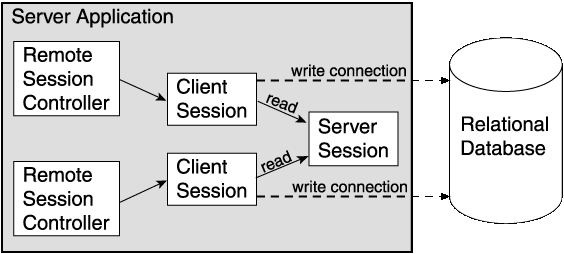
Both the client and server sessions reside on the server. Clients can communicate through any communication mechanism to the application server. On the application server the client always communicates with a client session that in turn communicates to the database through the server session. Figure 2-1 shows how the client and server sessions are used. Client and server sessions are independent of the communications mechanism and should be used in architectures including HTML, Servlet, JSP, RMI, CORBA, DCOM and EJB.
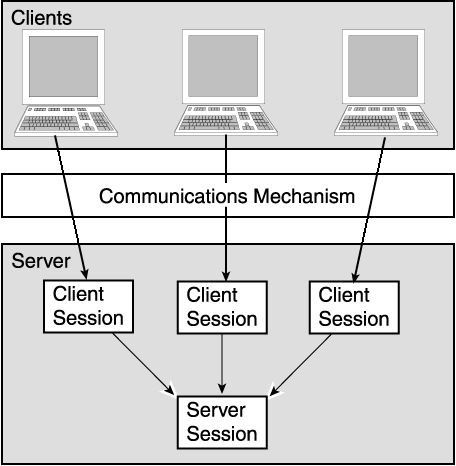
For a client to read objects from the database, it must acquire a ClientSession from the ServerSession or Server interface. This allows all client sessions to use the same shared object cache of the server session.
For a client to write objects to the database, it must acquire a ClientSession from the ServerSession or Server interface, and then acquire a UnitOfWork within that client session. The unit of work acts as an exclusive transactional object space. The unit of work ensures that any changes committed to the database through the unit of work are reflected in the server session's shared cache.
The server session or Server acts as the session manager for the three-tiered clients. The client session acts as a normal database session that is exclusive to each client or request.
For the most part, the client sessions are not used any differently than a normal TopLink database session. The client session supports all querying protocol that the database session supports.
Client sessions have two restrictions that are required to allow a shared object cache.
Users who have special security access (such as managers accessing salary information) cannot share the same cache as users who do not have access to that information. If multiple security levels exist, then a different server session must be used for each security level. Alternatively, non-shared database sessions could be used for each user with special security access.
A client session represents the dialog of one client with the server. The client session's lifecycle should mirror the lifecycle of the client. In a stateful three-tier model, the client session should exist until the client disconnects from the application server. In a stateless three-tier model, the client session should exist for the duration of one request of a client to the server. The client has exclusive access to the client session and should call the release() method on the client session object when it disconnects from the server. If notification of a disconnect cannot be guaranteed, the application server should time-out the connection to the client and force the client session to be released. If the client session garbage collects, it will automatically release itself.
Client sessions have many of the same properties as normal database sessions, but cannot use the following session properties:
Client sessions should not explicitly begin transactions, but instead should leverage the TopLink unit of work.
Client sessions should not use the SchemaManager.
Client sessions cannot add descriptors.
Client sessions should not explicitly write or delete from the database. The client must acquire a unit of work (see Chapter 6, "Performance Optimization") to be able to modify the database.
The server session manages the client session, shared cache and connection pools. Although the server session is a TopLink session it should only be used to manage the servers client sessions. For this purpose the Server interface is provided. The Server interface does not implement the session API but only the public API required for the server session such as configuring connection pools and acquiring client sessions.
Servers can create new client sessions using the acquireClientSession() method.
The data returned when a client reads an object is automatically cached on the server. This allows all client sessions to share a single cache stored in the server session's identity maps.
Ideally the SoftCacheWeakIdentityMap should be used. This identity map guarantees object identity. Because it uses weak references, it does not in itself impose memory requirements on the server. The SoftCacheWeakIdentityMap is available only if your VM supports the Java 2 API.
If the virtual machine (VM) being used does not implement the Java 2 API, then both the FullIdentityMap and CacheIdentityMap could be used. When using a full identity map, a reference is kept for all of the objects read in by all of the clients even after the reference is no longer needed. This imposes memory requirements on the server.
A possible solution to this problem is for the server system to periodically instruct TopLink to flush the cache. This can be done on a per instance or class basis, or for the identity map as a whole.
Another solution would be to use a cache identity map with a very large cache size. Objects that have been in the cache for a long period of time are eventually discarded. Note that this may lead to a loss of object identity. It is the responsibility of the server application to make sure that this does not occur by removing unnecessary references to objects in memory. Optimistic locking can also be used with a cache identity map to ensure that objects written to the database are not in an invalid state.
Once the client acquires a client session, it can send read requests to the server. If the server can satisfy the read request with information from its object cache, it returns the information back to the client. If the server cannot satisfy the request with information from its cache, it reads from the database and stores the information in its cache. Subsequent request for that information returns information from the fast object cache instead of performing resource intensive database operations.
This server structure allows for all clients and client sessions to share the same object cache and the same database connection pool for reading. The server should deal with each client request in a separate thread so that the database connection pool can be used concurrently by multiple clients.
Figure 2-2 illustrates how multiple clients can read from the database using the server session.
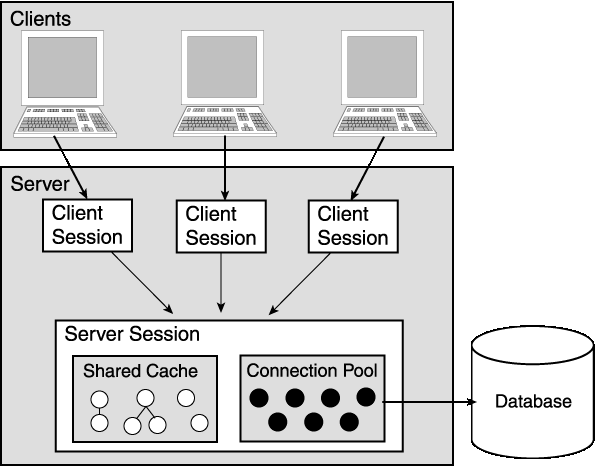
ServerSession object and call login() on it. This should be done only once, when the application server starts.
ClientSession from the ServerSession by calling acquireClientSession().
ClientSession object.
You should never use the ServerSession object for reading objects from the database.
When the client wants to write to the database, it must acquire its own object transaction space. This is because the client and server sessions allow all clients to share the same object cache and the same objects (see Figure 2-3).
The client session disables all database modification methods so that objects cannot be written or deleted. The client must obtain a unit of work from the client session to perform database modification.
The unit of work ensures that objects are edited under a separate object transaction space. This allows clients to perform object transactions in parallel. Once completed, the unit of work performs the changes in the database and then merges all of the changes into the shared TopLink cache in the session to make the changes available to all other users. Refer to Chapter 1, "Working with Database Sessions" for more information on unit of work.
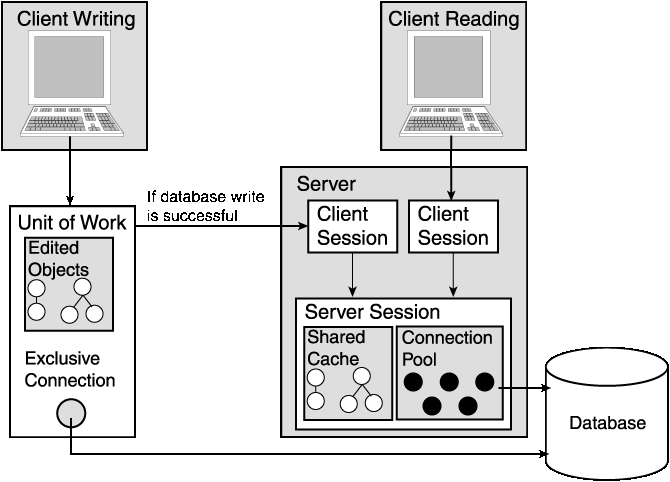
ServerSession object and call login() on it (this should be done only once, when the application server starts).
acquireClientSession()to acquire a ClientSession object from the ServerSession.
UnitOfWork object from the ClientSession object. Refer to Chapter 6 for more information on unit of work.
UnitOfWork.
To have concurrent clients logged in at the same time, the server must spawn a dedicated thread of execution for each client. The RMI and CORBA application servers do this automatically. Dedicated threads enable each client to perform its desired work without having to wait for the completion of other clients. TopLink ensures that these threads do not interfere with each other when they make changes to the identity map or perform database transactions.
TopLink addresses thread safety issues by using a concurrency manager for all of its critical components. The concurrency manager ensures that no two threads interfere with each other when altering critical data. Concurrency management is applied to crucial functions that include updating the cache when creating new objects, performing a transaction in the database, and accessing value holders.
Connection pooling allows for the number of connections used by the server and client sessions to be managed and shared among multiple clients. This reduces the number of connections required by the application server, allowing for a larger number of clients to be supported.
Multiple connections can also be allocated for reading. Although a single connection can support multiple threads reading asynchronously, some JDBC drivers may perform better when multiple connections are allocated. If multiple connections are used for reading, TopLink balances the load across all of the connections using a least-busy algorithm.
By default, TopLink uses a connection pool to manage the connections between client and server sessions:
The default number of connections is fairly low to maintain compatibility with JDBC drivers that do not support many connections. A larger number of connections should be used for both reading and writing if supported by the JDBC driver.
Some JDBC drivers do not support concurrency so may require a thread to have exclusive access to a JDBC connection when reading. The server session should be configured to use exclusive read connection pooling in these cases.
The server session also supports multiple write connection pools and non-pooled connections. If your application server or JDBC driver also supports connection pooling, the server session can be configured to integrate with this connection pooling.
The server session contains a pool of read connections and a pool of write connections that the client session may use. The number and behavior of each can be customized using the following ServerSession methods:
addConnectionPool(String poolName, JDBCLogin login, int minNumberOfConnections, int maxNumberOfConnections): creates a new connection pool and adds it to the pools managed by the ServerSession
useReadConnectionPool(int minNumberOfConnections, int maxNumberOfConnections): configures the read connection pool
useExclusiveReadConnectionPool(int minNumberOfConnections, int maxNumberOfConnections): configures the read connection pool to allow only a single thread to access each connection
setMaxNumberOfNonPooledConnections(int maxNumber): sets the maximum number of non-pooled connections
TopLink provides a connection policy object that allows the application to customize the way connections are used within a server session object.
There are four ways of getting connections from within a ClientSession object (these correspond to the four acquireClientSession() methods on the ServerSession):
ClientSession using the zero argument version of acquireClientSession(). This makes use of the default connection pool.
ClientSession by passing in a poolName as an argument to acquireClientSession(). This returns a ClientSession that uses a connection from the pool, poolName.
ClientSession by passing a DatabaseLogin object as an argument to acquireClientSession(). This returns a ClientSession that uses the DatabaseLogin object to obtain a connection.
These methods use a lazy database connection by default. This means that the connection is not allocated until a UnitOfWork is committed to the database. If you do not want to use a lazy database connection, but instead require that the database connection be established immediately, you must acquire a ClientSession by passing a ConnectionPolicy object as an argument to acquireClientSession(). This allows you to use any of the three connection options (by setting up the ConnectionPolicy object properly) but also allows you to specify a lazy connection.
The ConnectionPolicy class provides the following methods for configuring a client connection:
setPoolName(String poolName): Sets up a connection from the connection pool. Alternatively, this can also be accomplished using ConnectionPolicy(String poolName)
setLogin(DatabaseLogin login): Sets up a connection by loggin directly into the database. Alternatively, this can also be accomplished using ConnectionPolicy(DatabaseLogin login) of the connection policy constructor.
useLazyConnection(): specifies a lazy connection
setLazyConnection(boolean isLazy): specifies a lazy connection
dontUseLazyConnection(): specifies an active connection
Table 2-2 and Table 2-3 summarize the most common public methods for client and server session:
For a complete description of all available methods for client and server session, see the TopLink JavaDocs.
| Element | Default | Method Names |
|---|---|---|
|
Acquire Client Sessions |
not applicable |
acquireClientSession() |
|
Logging |
no logging |
logMessages() |
|
Login / logout |
not applicable |
login() logout() |
A remote session is a session that unlike other sessions actually resides on the client and talks to a server session on the server. Remote sessions handle object identity, proxies and the communication between the client and server layer.
Figure 2-4 shows the TopLink client/server split. Much of the application logic runs on the client. The middle, dotted layer is implemented by TopLink and the application interacts with the remote session.
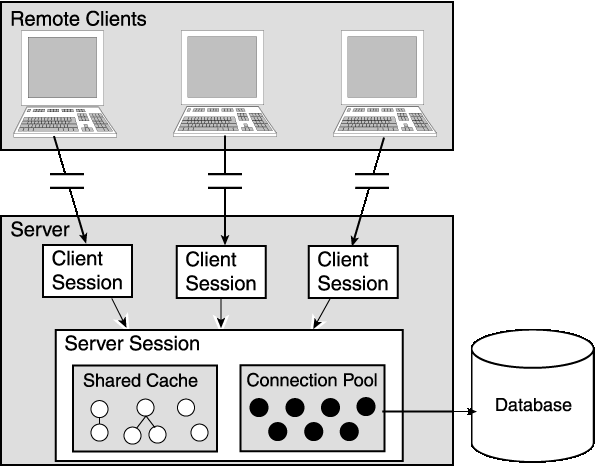
The remote session can interact to a database session or a client session (see Figure 2-5). This set-up is done on the server side, by the user. Interaction between the remote session and the database session is not very useful in a distributed environment, because only a single user can interact with the database. However, if the remote session interacts with the client session, then multiple remote sessions can interact with the single database. The remote session can also reap the benefits of connection pooling.
The model consists of the following layers (see Figure 2-6):
The request from the client application to the server travels down through the layers of distributed system. A client making a request to the server session actually makes use of the remote session as a conduit to the server session. The client holds reference to a remote session. If necessary, the remote session forwards a request to the server session via the transport and server layer.
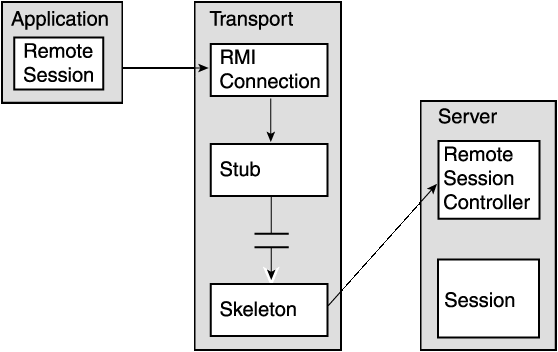
The application layer consists of the application and the remote session. The remote session is a subclass of the session. The remote session handles all the public protocols of the session, giving the appearance of working with the local database session.
The remote session maintains its own identity map and a hash table of all the descriptors read from the server. If the remote session is able to handle a request by itself, the request is not passed to the server. For example, a request to read an object that has already been read is processed by the remote session. However, if the object is being read for the first time, the request is passed to the server session.
The remote session interacts to the transport layer through a remote connection.
The transport layer is responsible for carrying the semantics of the invocation. It is a broker-dependant layer that hides all of the broker-related dependencies from the application and server layer.
It consists of a remote connection that is an abstract entity. All the requests to the server are forwarded though the remote connection. Each remote session holds on to a single remote connection. The remote connection marshals and unmarshals all requests and responses on the client side.
In an RMI system, the remote connection interacts with an RMI stub/skeleton layer to talk to the server layer.
Remote session supports communicating over RMI and CORBA. It includes deployment classes and stubs for RMI, WebLogic RMI, VisiBroker, OrbixWeb, WebLogic EJB and Oracle9i EJB.
The server layer consists of a remote session controller dispatcher, a remote session controller, and a session. The remote session controller dispatcher marshals and unmarshals all responses and requests from the server side. This is a server side component.
The remote session controller dispatcher is an interface between the session and transport layers. It hides the broker-specific transport layer from the session.
The accessibility of the server running on a remote machine is a very sensitive issue because security of the server is very important. In such an environment, registering a remote session controller dispatcher as service can be detrimental as anyone can get access to the service and therefore to the entire database. The recommended set-up is to run some sort of server manager as a service that holds the remote controller session dispatcher. All the clients talk to the server manager and it implements the security model for accessing the remote session controller dispatcher.
On the client side, the user can get access to the server manager as it is a public service running on the server. Once the client gets access to the server manager, it can ask for the remote session controller dispatcher. The manager returns one if it qualifies the security model built into the server manager.
A remote connection is then created using the remote session controller dispatcher on the client side. Once the connection is created, the remote session is acquired from the remote connection. The API for the remote session is same as for the session. For the user, there is no difference between working on a session or a remote session.
The remote session maintains lots of processing behavior so as to minimize its interaction with the server session. It maintains an identity map to preserve the identity of an object. At runtime, the remote session builds its knowledge base by reading descriptors and mappings from the server side only when they are needed. These descriptors and mappings are light-weight because not all of the information is passed on to the remote session. The information needed to traverse an object tree and to extract primary keys from the given object is passed with the mappings and descriptors.
Only read queries are publicly available on the client side. Object modification is done only through the unit of work.
Normal refreshing calls on the remote session force database hits and possible cache updates provided that the data were previously modified in the database. It could lead to poor performance and may refresh on queries when it is not desired; for example, the server session cache is positively known to be synchronized with the database.
Refresh operations against the server session cache are supported on the remote session. The descriptor can be configured to always remotely refresh the objects in the cache on all queries. This ensures that all queries against the remote session refresh the objects from the server session cache, without the database access.
Cache hits on remote sessions still occur on read object queries based on the primary keys. If these are not desired, the remote session cache hits on read object queries based on the primary key can be disabled.
// Remote session begin transaction remoteSession.beginTransaction(); // Get the PolicyHolder descriptor Descriptor holderDescriptor = remoteSession.getDescriptor(PolicyHolder.class); // Set refresh on the server session cache holderDescriptor.alwaysRefreshCachedOnRemote(); // Disable remote cache hits, ensure all queries go to the server session cache holderDescriptor.disableCacheHitsOnRemote();
Indirection objects are supported on the remote session. This is a special kind of value holder that can be invoked remotely on the client side. When invoked, the value holder first checks to see if the requested object exists on the remote session. If not, then the associated value holder on the server is instantiated to get the value that is then passed back to the client. Remote value holders are used automatically; the application's code does not change.
Cursored streams are supported remotely and are used in the same way as on the server.
All object modifications must be done through the unit of work that is acquired from the remote session. For the user, this unit of work is the same as a normal unit of work acquired from the client session or the database session.
The goal of the following example is to create a remote TopLink session on a client that communicates with a remote session controller on a server using RMI. Once the connection has been created, the client application can use the remote session as it would any other TopLink session.
We will assume we have created an object on the server called RMIServerManager (not part of TopLink). This class has a method that instantiates and returns a RMIRemoteSessionController (a TopLink server side interface).
The following client-side code gets a reference to our RMIServerManager and then uses this to get the RMIRemoteSessionController running on the server. The reference to the session controller is then used in creating our RMIConnection from which we get a remote session.
RMIServerManager serverManager = null;
// Set the client security manager
try {
System.setSecurityManager(new RMISecurityManager());
} catch(Exception exception) {
System.out.println("Security violation " + exception.toString());
}
// Get the remote factory object from the Registry
try {
serverManager = (RMIServerManager) Naming.lookup("SERVER-MANAGER");
} catch (Exception exception) {
System.out.println("Lookup failed " + exception.toString());
}
// Start RMIRemoteSession on the server and create an RMIConnection
RMIConnection rmiConnection = null;
try {
rmiConnection = new
RMIConnection(serverManager.createRemoteSessionController());
} catch (RemoteException exception) {
System.out.println("Error in invocation " + exception.toString());
}
// Create a remote session which we can then use as a normal TopLink Session
Session session = rmiConnection.createRemoteSession();
The following code is used by RMIServerManager to create and return and instance of an RMIRemoteSessionController to the client. The controller sits between the remote client and the local TopLink session.
RMIRemoteSessionController controller = null;
try {
// Create instance of RMIRemoteSessionControllerDispatcher which implements
RMIRemoteSessionController. The constructor takes a TopLink session as a
parameter.
controller = new RMIRemoteSessionControllerDispatcher (localTOPLinkSession);
}
catch (RemoteException exception) {
System.out.println("Error in invocation " + exception.toString());
}
return controller;
The session broker is the mechanism provided by TopLink for multiple database access. Using the session broker, you can store the objects within an application on multiple databases.
The session broker:
A two-phase commit is supported through integration with a compliant JTS driver (refer to the section "Java Transaction Service (JTS)" for more details). A true two-phase commit is guaranteed to entirely pass or entirely fail even if a failure occurs during the commit.
If there is no integration with a JTS driver, the broker uses a two-stage commit algorithm. A two-stage commit differs slightly from a two-phase commit. The two-stage commit performed by the session broker is guaranteed except for failure during the final commit of the transaction, after the SQL statement has been successfully executed.
After the session broker is set up and logged in, it is interacted with just like a session, making the multiple database access transparent. However, creating and configuring a SessionBroker is slightly more involved than creating a regular DatabaseSession.
Before using the SessionBroker, the sessions must be registered with it. To register a session with a SessionBroker, use the registerSession(String name, Session session) method. Before registration, all of the session's descriptors must have already been added to the session but not yet initialized. The sessions should not yet be logged in, as the session broker logs them in.
Project p1 = ProjectReader.read(("C:\Test\Test1.project")); Project p2 = ProjectReader.read(("C:\Test\Test2.project")); //modify the user name and password if they are not correct in the .project file p1.getLogin().setUserName("User1"); p1.getLogin().setPassword("password1"); p2.getLogin().setUserName("User2"); p2.getLogin().setPassword("password2"); DatabaseSession session1 = p1.createDatabaseSession(); DatabaseSession session2 = p2.createDatabaseSession(); SessionBroker broker = new SessionBroker(); broker.registerSession("broker1", session1); broker.registerSession("broker2", session2); broker.login();
When the login method is performed on the session broker, both sessions are logged in and the descriptors in both sessions are initialized. After login, the session broker is treated like a regular session. TopLink handles the multiple database access transparently.
UnitOfWork uow = broker.acquireUnitOfWork(); Test test = (Test) broker.readObject(Test.class); Test testClone = uow.registerObject(test); . . .//change and manipulate the clone and any of its references. . . uow.commit();//log out when finishedbroker.logout();
Using the session broker in a three-tier architecture is very similar to the way it is used in two-tier. However, the client sessions must also be registered with a SessionBroker. The ServerSessions are set up in a similar way.
Project p1 = ProjectReader.read(("C:\Test\Test1.project")) Project p2 = ProjectReader.read(("C:\Test\Test2.project")); Server sSession1 = p1.createServerSession(); Server sSession2 = p2.createServerSession(); SessionBroker broker = new SessionBroker(); broker.registerSession("broker1", sSession1); broker.registerSession("broker2", sSession2); broker.login();
A client session can then be acquired from the server session broker, through the acquireClientSessionBroker() method.
Session clientBroker = broker.acquireClientSessionBroker(); return clientBroker;
The session broker is designed to work with a project assigned to each session within the broker. There are a few ways to accomplish this in TopLink, but the following steps show the recommended approach.
Using the session broker is not the same thing as linking databases at the database level. If your database allows linking, that is the recommended approach to providing multiple database access.
The session broker has the following limitations:
Many-to-many join tables and direct collection tables must be on the same database as the source object, because a join across both databases would be required on a read. However, it is possible to get around this by using the setSessionName( method on
String sessionName)ManyToManyMapping and DirectCollectionMapping.
This method can be used to tell TopLink that the join table or direct collection table is on the same database as the target table.
Descriptor desc = session1.getDescriptor(Employee.class); ((ManyToManyMapping)desc.getObjectBuilder().getMappingForAttributeName("projects ")).setSessionName("broker2");
A similar method exists on DatabaseQuery that is used mostly for data queries (that is, non-object queries).
Table 2-4 summarizes the most common public methods for SessionBroker:
For a complete description of all available methods for SessionBroker, see the TopLink JavaDocs.
This section describes how TopLink for Java can be integrated with a transaction service satisfying the Java Transaction Service (JTS) API to participate in distributed transactions.
One of the important properties of databases is that transactions are atomic: a transaction either succeeds completely, or does not take effect at all. We get this automatically from most databases, but problems arise when we need to talk to more than one database at a time.
Consider the situation where we have bank accounts in two different databases. To transfer money from a checking account to a savings account, we want to withdraw money from an account in database A, and deposit it in an account in database B. We can use separate transactions for each database, but if a failure occurs on one database but not the other, then the balances will be incorrect. We need a single, unifying transaction that spans both databases.
Because updating information takes time and there is always a period during the transaction when the information is inconsistent, updating multiple databases may inevitably lead to situations where the information stored is inconsistent. A transaction can be described in more formal terms as a related set of operations with four properties. These are known by the acronym, "ACID":
All operations are considered as a unit, that is either all the operations complete, leaving the information in its consistent amended state (known as committing), or all the operations are undone, leaving the information in its original consistent state (known as rollback).
The operations take the information held from one consistent state to another in a predictable fashion.
The partially updated states of the information are not visible outside the transaction itself.
The outcome of the transaction is not reversed (partially or completely) after the transaction is completed.
When we described the banking transaction in the "Review of transactions and transaction management" , it was assumed that all of the information necessary to complete the transaction was available locally. However, there are many valid business reasons why information must be stored on different machines. Information may be distributed according to geography. For example, the Sales database may be divided into 'Northern Region' and 'Southern Region'. The information may be divided along departmental lines, with the Accounting department holding billing information while the Stock department holds inventory details. Whatever the reasons for distributing the information, the business user still requires that all of the ACID properties of 'regular' transactions are also true of distributed transactions.
In a non-distributed transaction, it is up to the single database to ensure the ACID properties of a transaction. In a distributed transaction there has to be careful co-operation between the various resources; thus The Open Group (formerly X/Open) has defined a formal model for Distributed Transaction Processing (DTP) known as the three box model. This model recognizes that there are three distinct components in a distributed transaction.
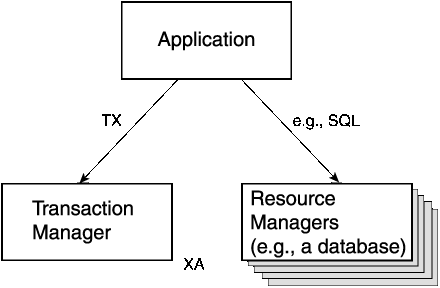
The application implements the business logic and does not have direct access to a database. Rather, it interacts with resource managers via a programming interface, typically SQL for relational databases. In addition, the application interacts with a transaction manager to begin and end a transaction. This sets up the transaction context within which all the components operate.
The resource managers have direct access to information and other database-specific resources. Typically a resource manager is a database, but it can be anything that is capable of transactional work (for example, a secure printer). The interface to the resource manager does not reveal any transaction details; rather, the resource manager interacts with the transaction manager to determine the current transaction context.
The transaction manager is dedicated to coordinating the activities of all of the participants in the transaction. It provides the TX interface so that applications can initiate transactional work. It co-ordinates the resource managers via the XA interface. The prime responsibility of the transaction manager is to guide the two-phase commit process that allows outstanding changes held by all the resource managers to be properly written to backing-store.
The two-phase commit with presumed rollback model (2-PC) allows resource managers to make temporary changes during the transaction so that they can be applied at the end of the transaction (committed) or undone (rolled back). During the transaction there is no ambiguity if a failure occurs -- all temporary changes are undone. When the transaction is committed by the application, then the temporary changes are made permanent in two phases.
In phase one, each resource (represented by a resource manager) is told to prepare. At this stage it must store in a secure way the changes it is about to make together with a secure record of its action. If it fails to do this, then it must vote rollback. If it succeeds in securing its records, then it must vote commit and wait for the final decision of the transaction manager. Once a resource has voted to commit, it gives up the right to rollback.
When all resources have voted on the outcome of the transaction or a failure has occurred, the transaction manager decides the final outcome of the transaction.
In phase two, each resource is told to commit. The resources must then make their temporary changes permanent and forget the record of their action made when they voted to commit. Once they have forgotten the secure record of the transaction, they can report done to the transaction manager. When the transaction manager has received done from all participants, it can forget the secure record of the transaction in its turn, and the transaction is complete.
The OMG Object Transaction Service defines interfaces that allow multiple, distributed objects to provide and participate in distributed ACID transactions. It is upon this specification that the Java Transaction Service (JTS) is based.
Transaction synchronization allows interested parties to get notification from the transaction manager about the progress of the commit. For each transaction started, an application may register a javax.transaction.Synchronization callback object that implements the following methods:
beforeCompletion method is called prior to the start of the two-phase transaction complete process. This call is executed in the same transaction context of the caller who initiates the begin.
afterCompletion method is called after the transaction has completed. The status of the transaction is supplied as the parameter. This method is executed without a transaction context.
The Synchronization interface described can be thought of as a lightweight `listener' to the lifecycle of the global external transaction. It is through this interface that TopLink can participate in a global external transaction by registering a Synchronization callback object for a unit of work.
The TopLink Session must be configured with an instance of a class that implements the ExternalTransactionController interface (from package oracle.toplink.sessions).
TopLink includes an external transaction controller for JTS 0.95. This controller is also compatible with JTS and JTA up to and including the JTA 1.0.1 specification. The controllers included with TopLink are found in the oracle.toplink.jts and oracle.toplink.jts.wls packages. These packages include generic JTS Listener and Manager classes, as well as classes that specifically support a number of databases and application servers including
If your JTS driver is not compatible with these versions you can build your own implementor of the ExternalTransactionController interface.
When using the JTS transaction controller, the transaction manager must be set in the JTSSynchronizationListener class. The transaction manager is required to give TopLink access to the global JTS transaction. Unfortunately there is no standard way to access the transaction manager so you must consult your JTS driver documentation to determine how to access this. When using the WebLogic JTS controller this is not required.
... (appropriate import stmts) Project project = Project.read("C:\myDir\myProj.project");// login specifics (database URL, etc) comes from the projectDatabaseLogin login = project.getLogin();/* set External behaviours: connectionPooling,Transaction mgmt, Transaction controller.Must be done before Session is created*/login.useExternalTransactionController(); login.useExternalConnectionPooling(); ServerSession session = project.createServerSession();// The transaction manager must be setJTSSynchronizationListener.setTransactionManagerjtsTransactionManager); session.setExternalTransactionController(new JTSExternalTransactionController()); ...
Use a Unit of Work to write to a database that uses JTS externally-controlled transactions. To do this successfully, however, you must ensure that there is only one unit of work associated with a given transaction. To do so, check for a transaction and associated unit of work as follows:
UnitOfWork uow = serverSession.getActiveUnitOfWork();
The following logic is executed:
From the example on the previous page, we can see that in addition to providing an ExternalTransactionController for the Session, the DatabaseLogin needs two additional properties configured:
useExternalTransactionController() - To interact correctly with a JTS service, we need to indicate to the DatabaseLogin object that transaction control is being managed by an external entity.
useExternalConnectionPooling() - It is common among JTS implementations that access to the service is `wrapped' and presented as a 'regular' JDBC driver. For example, the WebLogic JTS service is available as "weblogic.jdbc.jts.Driver". This driver (and its corresponding connection string "jdbc:weblogic:jts:{a_pool_name}" implements a pool of JDBC connections that can be configured separately from the login information (please consult the WebLogic product documentation for more information).
A user acquires a UnitOfWork from the TopLink session using the standard API acquireUnitOfWork(). Within acquireUnitOfWork(), registration of a Synchronization object with the current transaction is delegated to the ETC. If no global external transaction exists, the unit of work begins its own JTS transaction. In this case, if the unit of work is committed it also commits the JTS transaction that it began.
The user manipulates the UnitOfWork in the usual fashion, registering objects and altering clone copies (see "Using units of work" ). At this point, there are two scenarios to consider.
The user calls uow.commit() before the completion of the global external transaction - that is, neither Synchronization callbacks has yet occurred (see Figure 2-8).
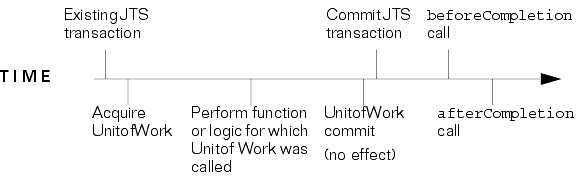
At uow.commit() time, a flag is set in the UnitOfWork indicating that a merge is pending. In the beforeCompletion callback, the appropriate SQL is sent to the database; if during this operation an OptimisticLockException (or some other RuntimeException) is thrown, the UnitOfWork is marked `dead' and the global external transaction is rolled back using the standard JTS APIs.
If the afterCompletion callback indicates success, the clones are merged with the TopLink Session. If the afterCompletion callback indicates failure (and possibly the beforeCompletion callback is not even invoked), the merge is not done and the UnitOfWork is released.
No global external transaction exists when the user acquires a unit of work (see Figure 2-9).
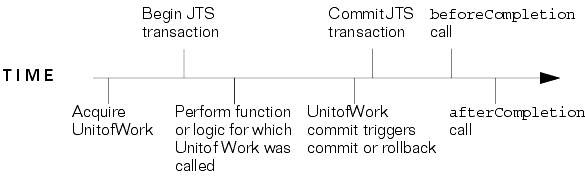
In this case, the beforeCompletion callback or the afterCompletion callback causes the unit of work to commit and if successful the afterCompletion callback causes the unit of work to merge its changes into the session cache. If the JTS transaction fails or is rolled back, the unit of work is released.
Since the JTS specification is new, vendors have implemented their JTS service against a changing backdrop, the JTS specification itself. To accommodate this, TopLink's JTS integration implementation is flexible to allow for local modifications.
A example of an implementation of a JTS External Transaction Controller is found in the package oracle.toplink.jts. Unfortunately, there needs to be different concrete implementations of the AbstractSynchronizationListener interface because the JTS specification has been changing recently. A vendor-specific implementation suitable for BEA WebLogic's JTS implementation is found in the package oracle.toplink.jts.wls.
In the package oracle.toplink.jts., two abstract classes form the basis of any local modifications:
Extensions to TopLink's JTS capabilities thus are always a pair of concrete classes that extend the named classes. A subclass of AbstractExternalTransactionController must implement the abstract methods from Table 2-6.
The register method performs a simple function - it delegates the call; it must invoke the static register method on the specific subclass of AbstractSynchronizationListener that is `paired' with the controller class - for example, the JTSExternalTransactionController implements register as follows:
public void register(UnitOfWork uow, SynchronizationListener sl, Session session) throws Exception { JTSSynchronizationListener.register(uow, sl, session); }
A subclass of AbstractSynchronizationListener must implement the two abstract methods from Table 2-6 as well as the static register method mentioned above.
Abstract methods of AbstractSynchronizationListener requiring concrete implementation for local JTS modifications
/** This method must be re-written for the concrete implementations of XXXSynchronizationListener as the various revisions of JTS that vendors have written their JTS implementations against have different ways of referring to/dealing with the 'Transaction' object */ public abstract void rollbackGlobalTransaction(); /** Examine the status flag to see if the Transaction committed. This method must be re-written for the concrete implementations of XXXSynchronizationListener as the various revisions of JTS that vendors have written their JTS implementations against have different status codes */ public abstract boolean wasTransactionCommited(int status);
For example, the JTSSynchronizationListener implements register as follows:
Prototypical implementation of register for JTS service
... import javax.transaction.*; ... public static void register(UnitOfWork uow, SynchronizationListener sl, Session session) throws Exception { Transaction tx = tm.getTransaction(); JTSSynchronizationListener jsl = new JTSSynchronizationListener(uow, sl,session,tx); tx.registerSynchronization(jsl); }
In the previous example implementation, the current global transaction is acquired from tm, a static variable local to JTSSynchronizationListener that must be set to an instance of a class that implements the javax.transaction.TransactionManager interface.
For the abstract methods, the JTSSynchronizationListener implements rollbackGlobalTx and txCommited as follows:
public void rollbackGlobalTransaction() { try { ((Transaction) globalTx).setRollbackOnly(); } catch (SystemException se) { } } public boolean wasTransactionCommited(int status) { if (status == Status.STATUS_COMMITTED)return true; else return false; }
To contrast, the WebLogicJTSSynchronization implements these methods as follows:
register for WebLogic's JTS service ...import weblogic.jts.common.*; import weblogic.jts.internal.*; import weblogic.jndi.*; import javax.naming.*; import java.util.*; import java.io.*; ... public static void register(UnitOfWork uow, Session session) throws Exception { Context ctx = null; Hashtable env = new Hashtable(); env.put(Context.INITIAL_CONTEXT_FACTORY, WEBLOGIC_FACTORY); env.put(Context.PROVIDER_URL,providerUrl);// these statics are null by default; check if someone set themif (principal != null)env.put(Context.SECURITY_PRINCIPAL,
principal); if (credentials != null) env.put(Context.SECURITY_CREDENTIALS,credentials); if (authentication != null)env.put(Context.SECURITY_AUTHENTICATION,
authentication); ctx = new InitialContext(env); Current current = (Current)ctx.lookup("javax.jts.UserTransaction"); WebLogicJTSSynchronization wjs = new WebLogicJTSSynchronization(uow,session,current); current.getControl().getCoordinator() .registerSynchronization(wjs); } public void rollbackGlobalTransaction() { ((Current) globalTx).setRollbackOnly(); } public boolean wasTransactionCommited(int status) { if (status == Synchronization.COMPLETION_COMMITTED) return true; else return false; }
TopLink provides an enterprise-proven architecture for the persistence of Java objects and JavaBeans to relational databases, object-relational databases and enterprise information systems. The TopLink architecture and API have evolved through over a decade of development and usage across many vertical markets, countries and applications. Included in this persistence architecture is support for Java Data Objects (JDO).
JDO is an API for transparent database access. The JDO architecture defines a standard API for data contained in local storage systems and heterogeneous enterprise information systems, such as ERP, mainframe transaction processing, and database systems. JDO enables programmers to create code in Java that transparently accesses the underlying data store without using database-specific code.
TopLink provides basic JDO support based on JDO Proposed final draft 1.0 specification (for information on the specification, see the Sun Microsystems web site at java.sun.com.
TopLink's support for JDO includes much of the JDO API, but does not require the class to be enhanced or modified by JDO Reference Enhancer aspects of the JDO specification and other JDO products.
The JDO API consists of four main interfaces:
A factory that generates PersistenceManagers. It has configuration and login API.
The main point of contact from the application. It provides API for accessing the transaction, queries and object life cycle API (makePersistent, makeTransactional, deletePersistent).
Defines basic begin, commit, rollback API.
Defines API for configuring the query (filter, ordering, parameters, and variables) and for executing the query.
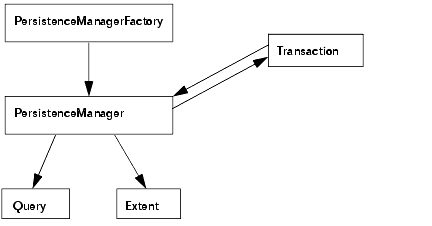
TopLink implements the main JDO interfaces PersistenceManagerFactory, PersistenceManager, and Transaction. It extends the query functionality to include the complete TopLink query framework. The supported APIs are listed in the reference tables of their respective implementation class. JDO APIs that are not listed in the reference tables are not supported.
For more information on the TopLink query framework, see "Using the query framework" .
The JDOPersistenceManagerFactory class implements a JDOPersistenceManagerFactory. This factory creates PersistenceManagers.
To create a JDOPersistenceManagerFactory, the constructor takes a session name string or a TopLink session or project. If the factory is constructed from a project, a new DatabaseSession is created and attached to the PersistenceManager every time it is obtained through the getPersistenceManager method.
The PersistenceManager is not multi-threaded. For multi-threaded application, each thread should have its own PersistenceManager. The JDOPersistenceManagerFactory should be constructed from a ServerSession not DatabaseSession or Project to make use of the lighter weight client session and more scalable connection pooling.
The following code creates a factory from a TopLink session named "jdoSession" that is managed by SessionManager. The SessionManager manages a singleton instance of TopLink ServerSession or DatabaseSession named "jdoSession". Refer to SessionManager documentation for more info.
JDOPersistenceManagerFactory factory= new JDOPersistenceManagerFactory("jdoSession");
//Create a persistence manager factory from an instance of TopLink ServerSession or DatabaseSession that is managed by the user.//
ServerSession session = (ServerSession) project.createServerSession(); JDOPersistenceManagerFactory factory= new JDOPersistenceManagerFactory(session);
//Create a persistence manager factory with ties to a DatabaseSession that is created from TopLink project.//
JDOPersistenceManagerFactory factory= new JDOPersistenceManagerFactory(new
EmployeeProject());
New PersistenceManagers are created by calling the getPersistentManager method. If the factory is constructed from a Project instance, it can also configure the userid and password using getPersistentManager(String userid, String password).
Table 2-7 summarizes the most common public methods for PersistenceManagerFactory:
For a complete description of all available methods for PersistenceManagerFactory, see the TopLink JavaDocs.
The JDOPersistenceManager class implements a JDOPersistenceManager, the primary interface for JDO-aware application components. The JDOPersistenceManager is the factory for the Query interface and contains methods for accessing transactions and managing the persistent life cycle instances. The JDOPersistenceManager instance can be obtained from JDOPersistenceManagerFactory.
New JDO objects are made persistent using the makePersistent() or makePersistentAll() methods. If the user does not manually begin the transaction, TopLink will begin and commit the transaction when either makePersistent() or makePersistentAll() is invoked. Note that if the object is already persisted, calling these methods has no effect.
Server serverSession = new EmployeeProject().createServerSession(); PersistenceManagerFactory factory = new JDOPersistenceManagerFactory(serverSession); PersistenceManager manager = factory.getPersistenceManager(); Employee employee = new Employee(); employee.setFirstName("Bob"); employee.setLastName("Smith"); manager.makePersistent(employee);
JDO objects are modified using a transactional instance. The object is modified within a transaction context by manually beginning and committing the transaction.
A transactional object is an object that is subject to the transaction boundary. Transactional objects can be obtained several ways, including
getObjectById()
getTransactionalObject()
The transactional-read query is a query that is executed when the nontransactionalRead flag of the current transaction is false. The current transaction is obtained from the PersistenceManager by calling currentTransaction().
The following example illustrates how to add a new phone number to an employee object, modify its address and increase its salary by 10%.
Transaction transaction = manager.currentTransaction();
if(!transaction.isActive()) {
transaction.begin();
}
// Get the transactional instance of the employee//
Object id = manager.getTransactionalObjectId(employee);
Employee transactionalEmployee = manager.getObjectById(id, false);
transactionalEmployee.getAddress().setCity("Ottawa");
transactionalEmployee.setSalary((int) (employee.getSalary() * 1.1));
transactionalEmployee.addPhoneNumber(new PhoneNumber("fax", "613", "3213452"));
transaction.commit();
JDO objects are deleted using either deletePersistent() or deletePersistentAll(). The objects can be transactional or non-transactional. If the user does not manually begin the transaction, TopLink will begin and commit the transaction when deletePersistent () or deletePersistentAll () is invoked.
It is important to understand that deleting objects using deletePersistent() or deletePersistentAll() is similar to deleting objects using UnitOfWork. When an object is deleted, its privately-owned parts are also deleted, because privately-owned parts cannot exist without their owner. At commit time, SQL is generated to delete the objects, taking database constraints into account. If an object is deleted, then the object model must take the deletion of that object into account. References to the object being deleted must be set to null or removed from the collection. Modifying references to the object is done through its transactional instance.
Transaction transaction = manager.currentTransaction();
if(!transaction.isActive()) {
transaction.begin();
}
Object id = manager.getTransactionalObjectId(projectNumber);
Project transactionalProject = (Project) manager.getObjectById(id);
Employee transactionalEmployee = transactionalProject.getTeamLeader();
// Remove team leader from the project//
transactionalProject.setTeamLeader(null);
// Remove owner that is the team leader from phone numbers//
for(Enumeration enum = transactionalEmployee.getPhoneNumbers().elements();
enum.hasMoreElements();) {
((PhoneNumber) enum.nextElement()).setOwner(null);
}
manager.deletePersistent(transactionalEmployee);
transaction.commit();
Transaction transaction = manager.currentTransaction(); if(!transaction.isActive()) { transaction.begin(); } Object id = manager.getTransactionalObjectId(phoneNumber); PhoneNumber transactionalPhoneNumber = (PhoneNumber) manager.getObjectById(id); transactionalPhoneNumber.getOwner().getPhoneNumbers().remove(transactionalPhoneN umber); manager.deletePersistent(phoneNumber); transaction.commit();
TopLink does not support the JDO Query language but instead includes support within JDO for the more advanced TopLink query framework (for information on the TopLink query framework, see "Using the query framework" ). A key difference is that, while the JDO query language requires results to be returned as a collection of candidate JDO instances (either a java.util.Collection,or anExtent, the result type returned by the TopLink query framework depends on the type of query used. For example, if a ReadAllQuery is used, the result is a Vector.
The query factory is supported through the following APIs.
newQuery();newQuery(Class persistentClass);
newQuery(Class persistentClass, Expression expressionFilter);
A ReadAllQuery is created with the Query instance by default.
Table 2-8 and Table 2-9 summarize the most common public methods for the Query API and TopLink extended API:
For a complete description of all available methods for the Query API and TopLink extended API, see the TopLink JavaDocs.
The JDOQuery class implements the JDO Query interface. It defines API for configuring the query (filter, ordering, parameters, and variables) and for executing the query. TopLink extends the query functionality to include the full TopLink query framework (for information on the TopLink query framework, see "Using the query framework" ). Users can customize the query to use advanced features such as batch reading, stored procedure calls, partial object reading, query by example, and so on. TopLink currently does not support the JDO query language, but users can use either SQL or EJBQL in the JDO Query interface. For more information on EJBQL support, see Chapter 4, "EJBQL Support".
Each JDOQuery instance is associated with a TopLink query. When the JDO Query is obtained from the PersistenceManager by calling a supported newQuery method, a new ReadAllQuery is created and associated with the query. JDO Query can reset its TopLink query to a specific type by calling asReadObjectQuery(), asReadAllQuery(), or asReportQuery.
Much of the TopLink query framework functionality is provided through the public API. In addition, users can build complex functionality into their queries by customizing their own query. Users can create customized a TopLink query and associate it with the JDO Query by calling setQuery().
Using a customized TopLink query gives users the complete functionality of TopLink query framework. An example for using customize query is using a DirectReadQuery with custom SQL to read the id column of the employee.
|
Note: TopLink extended APIs are configured for a specific TopLink query type. Exception could be thrown if methods are used with the wrong query type. See Table 2-10 for correct usage. |
Expression expression = new ExpressionBuilder().get("address").get("city").equal("New York"); Query query = manager.newQuery(Employee.class, expression); Vector employees = (Vector) query.execute();
Expression exp1 = new ExpressionBuilder().get("firstName").equal("Bob"); Expression exp2 = new ExpressionBuilder().get("lastName").equal("Smith "); JDOQuery jdoQuery = (JDOQuery) manager.newQuery(Employee.class); jdoQuery.asReadObjectQuery(); jdoQuery.setFilter(exp1.and(exp2)); Employee employee = (Employee) jdoQuery.execute();
JDOQuery jdoQuery = (JDOQuery) manager.newQuery(Employee.class);
jdoQuery.asReportQuery();
jdoQuery.addCount();
jdoQuery.addMinimum("min_salary ",
jdoQuery.getExpressionBuilder().get("salary"));
jdoQuery.addMaximum("max_salary",
jdoQuery.getExpressionBuilder().get("salary"));
jdoQuery.addAverage("average_salary",
jdoQuery.getExpressionBuilder().get("salary"));
// Return a vector of one DatabaseRow that contains reported info
Vector reportQueryResults = (Vector) jdoQuery.execute();
DirectReadQuery TopLinkQuery = new DirectReadQuery();
topLinkQuery.setSQLString("SELECT EMP_ID FROM EMPLOYEE");
JDOQuery jdoQuery = (JDOQuery) manager.newQuery();
jdoQuery.setQuery(topLinkQuery);
// Return a Vector of DatabaseRows that contain ids
Vector ids = (Vector)jdoQuery.execute(query);
Table 2-10 and Table 2-11 summarize the most common public methods for the JDO Query API and TopLink extended API:
For a complete description of all available methods for the JDO Query API and TopLink extended API, see the TopLink JavaDocs.
The JDOTransaction class implements the JDO Transaction interface, and defines the basic begin, commit, and rollback APIs, and synchronization callbacks within the UnitOfWork. It supports the optional non-transactional read JDO feature.
The read mode of a JDO transaction is set by calling the setNontransactionalRead() method.
The read modes are:
Non-transactional reads provide data from the database, but do not attempt to update the database with any changes made to the data when the transaction is committed. This is the default transaction mode from PersistenceManagerFactory. Non-transactional reads support nested Units of Work.
When queries are executed in non-transactional read mode, their results are not subject to the transactional boundary. To update objects from the queries' results, users must modify objects through their transactional instances.
To enable non-transactional read mode, set the non-transactional read flag to true.
Transactional reads provide data from the database and writes any changes to the object back to the database when the transactions commits. When transactional read is used, TopLink uses the same UnitOfWork for all data store interaction (begin, commit, rollback). This can cause the cache to grow very large over time, so this mode should be only used with short-lived PersistenceManager instances to allow the UnitOfWork be garbage collected.
When queries are executed in transactional read mode, their results are transactional instances and they are subject to the transactional boundary. Objects can be updated from the result of a query that is executed in transactional mode.
Because the same UnitOfWork is used in this mode, the transaction is always active and must be released when the read mode is changed from transactional read to non-transactional read.
To enable transactional read mode, set the non-transactional read flag to false.
A Synchronization listener can be registered with the transaction to be notified at transaction completion. The beforeCompletion and afterCompletion methods are called when the pre-commit and post-commit events of the UnitOfWork are triggered respectively.
TopLink includes a demo that illustrates some of the JDO functionality. oracle.toplink.demos.employee.jdo.JDODemo is based on the project oracle.toplink.demos and is configured to connect to a Microsoft Access database. The database connection code is in the
.employee.relational.EmployeeProjectapplyLogin() method of the EmployeeProject class. You may have to modify this method if you do not have a Microsoft Access database, or if the connection information for your database is different from what is specified in this code. When the database connection is setup properly, you can start running the JDO demo.
Within a distributed application environment, the correctness of the data that is available to clients is very important. This issue increases in complexity as the number of servers within an environment increases. To reduce the occurrences of incorrect data ("stale" data) being delivered to clients, TopLink provides a cache synchronization feature. This feature ensures that any client connecting to a cluster of servers is able to retrieve its changes, made through a UnitOfWork, from any other server in the cluster (provided that no changes have been made in the interim).
When enabled in a distributed application, changes made in one transaction on a particular node of the application is broadcast to all other nodes within the distributed application. This prevents stale data from spanning transactions and greatly reduces the chance that a transaction will begin with stale data.
Cache Synchronization in no way eliminates the need for an effective locking policy but does reduce the number of Optimistic lock exceptions and can therefore dramatically decrease the amount of work that must be repeated by the application.
Cache synchronization complements the implemented locking policies and can propagate changes synchronously or asynchronously.
The Cache Synchronization Manager offers several options for controlling the synchronized sessions:
| Use this code fragment... | To... |
|---|---|
setIsAsynchronous (boolean isAsynchronous) |
Set propagation mode. See "Synchronous versus asynchronous updates" . |
setShouldRemoveConnectionOnError (boolean removeConnection) |
Drop connections in the event of a communication error. See "Error handling" . |
addRemoteConnection (RemoteConnection connection) |
Add new connections to the synchronized cache. See "Advanced options: Managing connections" . |
getRemoteConnections() |
Get remote connections. See "Advanced options: Managing connections" . |
removeAllRemoteConnections() |
`Remove all remote connections from the cache synchronization service. See "Advanced options: Managing connections" . |
removeRemoteConnection (RemoteConnection connection) |
Remove a specific remote connection. See "Advanced options: Managing connections" . |
connectToAllRemoteServers() |
Connect to all servers participating in cache synchronization. See "Deprecated options: Connecting to all remote servers" . |
With the Session properties set, the session automatically connects to all other sessions that are on the same network when the session logs in. Any changes made as a result of the session is then broadcast to all other servers on the same network.
The Cache Synchronization Manager enables you to specify two important functions: the update method for the servers in the caching service, and the error handling method used to control communication errors.
The CacheSynchronizationManager enables you to specify how other sessions are updated when changes are made on a given node:
The Cache Synchronization Manager offers very simple error handing: you can set it to drop connections in the event of a communications error.
The Cache Synchronization Manager includes several advanced API options for managing connections. These options are listed in Table 2-12, and enable you to get or add connections, as well as remove specific connections or all connections from a cache synchronization service. Note that these options are considered advanced functionality that is not typically required to run a cache synchronization pool.
The Cache Synchronization manager continues to support the connectToAllRemoteServers functionality. However, this support should be considered only as a service to legacy applications, and not added to new ones.
The clustering services for cache synchronization have the following attributes:
The IP used by the sessions for multicast communications. All sessions that share the same Multicast group IP and address will send changes to each other
Port used for Multicast communication
This is the number of 'hops' that a multicast packet will make on the network before stopping. This has more to do with network configuration than the number of nodes connected
This setting is used by the ClusteringService to determine how long to wait between making the Remote Service available and announcing its existence. This is required in systems where there is propagation delay when binding the services into JNDI.
You can implement a custom Clustering Service to support cache synchronization. This advanced option must respond and be usable as a Foundation Library supplied Clustering Service. Custom Clustering services, include the all of the components of a regular clustering service (multicast group IP, multicast port, and Time to Live Setting).
To configure an TopLink Session to use Cache Synchronization, set the Session to use a Cache Synchronization Manager with a particular Clustering Service in the Session properties. This class controls the interaction with other Sessions including accepting changes and connections from Sessions and sending information to all other Sessions.
The Cache Synchronization Manager requires the URL of the naming service. The Clustering Services are organized by communication framework then by naming service. The implementations shipped with the Foundation Library are as follows:
If you need to implement your own proprietary communications protocol, consult the RMIRemoteSessionControllerDispatcher and RMIRemoteConnection classes shipped with TopLink.
The Session may also be configured through code.
session.setCacheSynchronizationManager(new
oracle.toplink.remote.CacheSynchronizationManager () );
// simple URL used for RMI registry
session.getCacheSynchronizationManager().setLocalHostURL("localhost:1099");
session.getCacheSynchronizationManager().setClusteringServiceClassType(oracle.to
plink.remote.rmi.RMIClusteringService.class);
session.setCacheSynchronizationManager( new oracle.toplink.remote. CacheSynchronizationManager());//simple URL used for RMI registrysession.getCacheSynchronizationManager(). setLocalHostURL("localhost:1099");// Set up Clustering Service with non default multicast group. Note that the multicast group must start with 226.x.x.x and can not be 226.0.0.1. The port can be any value. Set the same multicast IP and port number for all sessions that you wish to synchronizeRMIClusteringService clusteringService = new RMIClusteringService("226.3.4.5", 3456, session); session.getCacheSynchronizationManager().setClusteringService(clusteringService) ;
CacheSynchronizationManager.
ServerSession.
RemoteSessionDispatcher, and add this dispatcher to the CacheSynchronizationManager.
RemoteSessionDispatcher available in a global space such as the RMI registry.
This session is now able to receive synchronization updates and new connections from other servers.
RemoteConnection for the communications framework.
RemoteSessionDispatcher of a session that is to be synchronized with.
RemoteConnection to the CacheSynchronizationManager.
The current server connects to the owner session of the dispatcher, and adds that server to the list of servers to synchronize with.
The distributed session is automatically notified of this session's existence, and adds this session to its list of synchronization participants.
CacheSynchronizationManager synchManager = new CacheSynchronizationManager(); getSession().setCacheSynchronizationManager(synchManager); RMIRemoteSessionControllerDispatcher controller = new oracle.toplink.remote.rmi.RMIRemoteSessionControllerDispatcher(getSession()); synchManager.setSessionRemoteController(controller);//Lookup and connect to another SessionRemoteConnection connection = new RMIConnection((RMIRemoteSessionController)registry.lookup("Server2"));//connect to the distributed session and notify that server of this session's existencegetSession().getCacheSynchronizationManager().addRemoteConnections(connection);//Here I am making the current Server available in the Registry your implementation of distributing the RemoteSessionDispathcer may differregistry.rebind("Server1", controller);
Java Messaging Service (JMS) is a a specification that provides developers with a pre-implementation and specification of many common messaging protocols. JMS can also be used to build a more scalable cache synchronization implementation.
TopLink integrates with the JMS publish/subscribe mechanism. For more information on this mechanism, consult the JMS specification available on the Sun web site (http:\www.sun.com).
A JMS service must be set up outside of TopLink before TopLink can leverage the service. To set the service up the developer must
These steps are completed in the software that provides the JMS service. For more information on completing these steps, see the documentation provided with that software.
JMS messaging is typically established in the session configuration file (for example sessions.xml) although it can also be set up in code.
The following example illustrates the use of all JMS options in a typical sessions.xml file:
<cache-synchronization-manager> <clustering-service>oracle.toplink.remote.jms
.JMSClusteringService</clustering-service> <should-remove-connection-on-error>false
</should-remove-connection-on-error><!-- both of the following tags are user specified and must correspond to the settings that the user has made, manually, to the JMS Service --><jms-topic-connection-factory-name> TopicConectionFactory
</jms-topic-connection-factory-name> <jms-topic-name> TopLinkCacheSynchTopic
</jms-topic-name><!-both of the following tags may be required if TopLink is not running in the same VM as the JNDI service --><naming-service-url>t3://localhost:7001
</naming-service-url> <naming-service-initial-context-factory>weblogic.jndi.WLInitialContextFactor y </naming-service-initial-context-factory> </cache-synchronization-manager>
JMS support includes new API calls. The following API is required to implement JMS in Java:
public void setTopicConnectionFactoryName(String jndiName); public void setTopicName(String topicName);
If the JMS is not running on the same virtual machine as the JNDI service, you may also have to include the following:
public void setLocalHostURL(String jndiServiceURL); public void setInitialContextFactoryName(String initialContextFactoryName);
The following example illustrates a typical implementation of JMS:
this.session.setCacheSynchronizationManager(new oracle.toplink.remote.CacheSynchronizationManager()); JMSClusteringService clusteringService = new oracle.toplink.remote.jms.JMSClusteringService(this.session); clusteringService.setLocalHostURL("t3://localhost:7001"); clusteringService.setTopicConnectionFactoryName("TopicConectionFactory"); clusteringService.setTopicName("TopLinkCacheSynchTopic"); this.session.getCacheSynchronizationManager().setClusteringService(clusteringSer vice);
|
|
 Copyright © 2002 Oracle Corporation. All Rights Reserved. |
|